
This time, I'm going to introduce you to a very cool open source tool with which you can create your own machine learning (ML) models, train them, and then use them to test some important aspect—presumably security—in your organization. Because just about every organization is subject to spam and phishing, I'll show you how to use this tool to identify probable phishing websites.
The tool we'll be using is Weka. Weka is the Waikato Environment for Knowledge Analysis from Waikato University in New Zealand. Weka also is a small native bird, but that's just one of those fun facts that you can use if you're on "Jeopardy" (…what is a weka?).
You can download Weka from Sourceforge at https://sourceforge.net/projects/weka/. There is also a bounty of information about it and machine learning on the site. For the download, go to the "Files" tab. For this blog, I'll use Weka 3.8.4, but version 3.9 is available on the site. The Weka website is https://www.cs.waikato.ac.nz/ml/weka/. For a LOT more ML information, tutorials, and good AI information, see Machine Learning Mastery: http://MachineLearningMastery.com.
I'm not going to spend time showing you how to install Weka because there is almost nothing to it. We'll begin by giving the tool the once-over, then we'll use it to help identify phishing websites. I am not going to make this an ML tutorial; we've done that before, and even so, there is a lot of great ML information on the Web, so I'll leave it to you to dig into that if you wish. For my part, I'll explain the aspects of ML that we need to use with Weka. So let's get started.
Getting ready
Of course, you need an installed version of Weka, but you also need data. That usually comes in the form of some sort of database or dataset, but it likely is not particularly useful in its original form. This is especially true when the data are freeform as is the case with spam emails. So we must begin by creating a new dataset that we can use to train Weka. That dataset should be fairly large and consist of examples that are bad and examples that are good. In our case, we want verified phishing websites and verified legitimate webpages. Then we need to figure out what makes the phishing websites phishing and create a new database of those attributes. We call those attributes "features," and the process is feature extraction. There is open source software available for that, or, if you are proficient in a language such as Python, you can write your own.
Before we can extract features, however, we need to identify them. There do not need to be many, but many are okay if the definition they are using is complicated. For example, our data for identifying phishing contains 49 different features. Our dataset contains 5,000 phishing examples and 5,000 legitimate examples. The feature set to be extracted is based upon the verified phishing websites. Figure 1 shows the extracted features for our phishing project.
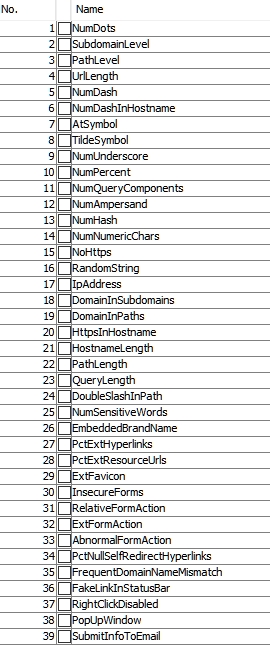
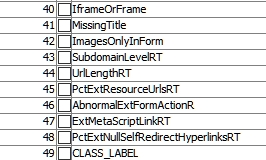
Figure 1 - Attributes used for feature selection in our phishing dataset
In our example, the last attribute is important because it identifies a site as phishing or legit. A little later when we have a test dataset, we will replace the last feature with a question mark indicating that we do not know if the site being tested is phishing or legitimate. So, a site's attributes may look like Figure 2:
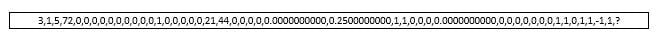 Figure 2 - Feature extraction for the website being tested (Note, the ? as the last character in the comma-separated data)
Figure 2 - Feature extraction for the website being tested (Note, the ? as the last character in the comma-separated data)
In Figure 2, we have a value for each attribute in our extracted feature set. This is a CSV file as viewed in Excel, but Weka uses a similar file format called AARF (Attribute-Relation File Format). Weka and AARF support four data types:
• numeric (includes integer and real)
• Nominal specification (listing the possible values such as nominal-name1, nominal-name2, etc.)
• String
• Date
It will also, in the future, support relational for multi-instance data.
So, examining the values in Figure 2, we see that it appears that all values are numeric except the final one (the ?). Using Weka's Explorer, we find that this value -CLASS_LABEL- is Nominal. Our label choices are Legit and Phishing. So the @attribute expression (attributes in AARF are preceded by "@") would be:
@attribute CLASS_LABEL {Legit,Phishing}
So Figure 3 shows a line of CSV attributes that ends with the CLASS_LABEL Phishing. Since that is what we want to find out, we will feed our model an attribute set of features extracted from unknown websites and let the model decide which are phishing sites and which are legitimate.
 Figure 3 - A CSV attribute set showing the final element as phishing
Figure 3 - A CSV attribute set showing the final element as phishing
Our training dataset contains 10,000 lines of attributes (the features of the original website analysis are extracted to populate our AARF feature set of attributes). Now to use that training set to build a model. Once the model is built—it's binary, so we cannot easily show it here—we can use it to classify an unknown site with its features extracted into an AARF file. This is a known dataset, so it is supervised learning.
We will need two AARF files: one that contains our training set, and one that contains our questioned sites. We could get into a lot more detail about the meanings of the individual elements or attributes, but with 49 of them that would get vary tedious in a hurry. So I'll give a baby example from the line of attributes in Figure 3.
The first attribute is 3. Weka tells us that it is a numeric attribute with a minimum value of 1 and a maximum value of 8. Those are not arbitrary selections; they are extracted from the dataset. The name of the attribute is NumDots. In this case, that means that the number of dots (i.e., the number of levels deep in the URL) is 3. The researcher determined that the number of levels beyond a certain number is a phishing indicator. The next attribute, 1, is SubdomainLevel. It shows how far the subdomain is removed from the root URL. In this case, the number is 1. The actual findings throughout the training set range from 0 to 7 according to Weka. The rest have similar explanations.
Building, saving, and using the model
Our first task is to feed Weka our training set. We do that through the Explorer; see Figure 4.
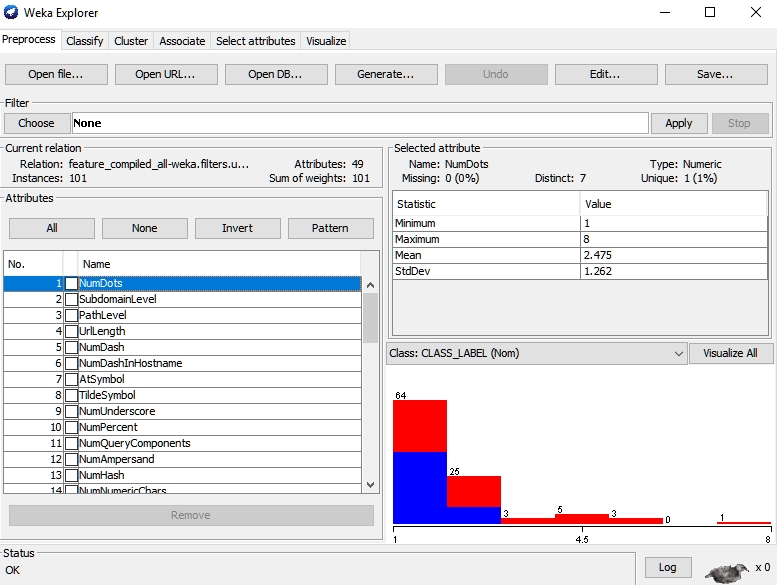
Figure 4 - Weka Explorer, preprocessing our dataset
Our next step is to run the Classifier, again from the Explorer (second tab). We are going to run it on our training set choosing the RandomForest classifier because the researcher reported finding the best results with that classifier. If you are building a new, and different, model, you will need to experiment with the various available classifiers in Weka.
This will create our model for determining whether a site is phishing or legitimate. We right-click on the result list on the Classify tab and select Save Model from the drop-down menu. We give it a name and a location and save it. In our case, I simply called my model Phishing. It was saved as Phishing.model.
Now we need to load the model into Weka, feed it our test set, and get a result. I took the results for clarity here and transferred them to an Excel file using CSV after I cleaned up the result file a bit. Figure 5 shows a piece of that result set.
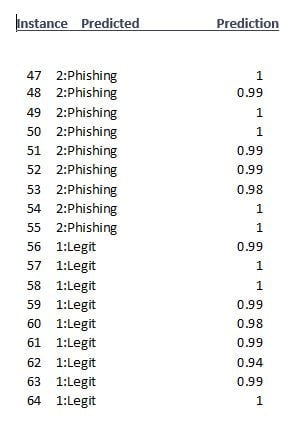
Figure 5 - Phishing test result set (partial)
Note that the third column gives us a "Prediction." This is a probability that the classifier's decision is correct. I saved this in text and saved it to an Excel file, but you have several choices: CSV, HTML, not to save at all, plain text, or XML. I saved just 101 instances, meaning that I tested 101 unknown webpages.
Conclusions
In this blog, we looked at a tool to build your own machine learning models and use them. Our example was phishing webpages, something that is both useful and hits a lot of high points with the tool and the process. Our base information and datasets came from Choon Lin Tan, the researcher who put this project together as part of a much larger research project. You can read more and get the data at https://data.mendeley.com/datasets/h3cgnj8hft/1. The tool is very simple to use and there is a wealth of information about it on the Sourceforge site.
As you look around your organization for useful Weka projects, focus on things that are created in large batches—such as visits to phishing websites—and that you can create a training set for. Get or build a feature extractor that suits your application, and make machine learning a customized part of your security program.



